I finally found out what the difference is between Machine Language, Assembly and Assembler – and how it fits in with Interpreters and Compilers. For those of you game enough, let me explain what these cryptic terms mean – and how they span computers from the early C64 to today’s high-end laptops.
Interpreters
Something that has plagued the early computers was their speed of how they executed things in BASIC – or rather the lack thereof. As nice as BASIC is, sifting through an array of variables can compare them with a known value does take some time.
That’s not BASIC’s fault though – it’s rather the way it is executed. You see, BASIC (on the C64 and his comrades) is an interpreted language. This means that while the computer is working, it’s translating the BASIC statements into something it can actually understand – which is of course not BASIC. All a computer really knows is if something’s ON or OFF. Computers are truly binary machines – no matter how old or how new they are. So if you tell them to PRINT “HELLO” then some translation work needs to happen for HELLO to appear on the screen – and that takes time.
That’s what an interpreter does: translate one language into another on the fly – much like people can listen in Spanish, and speak the same thing in English, for the benefit of an audience (usually not for their own pleasure).
The great thing about interpreted languages is that the source code always remains readable. As you can imagine, ultimately the interpreter will throw some ones and zeros at the computer. There’s no way you could make a change to that as it bears no resemblance to your source code.
One alternative to speeding up the programme in question would be to have the something like the interpreter to go to work BEFORE the programme is executed. Ahead of time, and in its own time. Then we could present the translated result to the computer right away, taking away the “on-the-fly” translation and saving some CPU power. I guess it won’t come as a big surprise that this is done frequently too: it’s called compiling, and a Compiler does such a job.
Another alternative would be to not write in language A and then translate into language B – but write directly in something that the computer understands. Namely “machine language”.
And some humans are brave enough to do this. Some even think it’s a nice challenge!
Why would anyone do this?
Fair question – why would we talk directly to the processor in a language so alien to us. Speed of execution, full control over how something is executed for example. But also because it’s fun to speak natively. I’d hate to be a politician having to rely on a translator to interpret what the other head of state is trying to say, because I’d hate to miss out on what’s commonly “lost in translation”.
The more interesting question is “how do we do this?” What does the computer “speak” if it’s not BASIC? And how to I ask him to do anything?
Those have been questions I’ve been asking myself, and I’m happy to share with you what I’ve found out.
Speaking to your CPU
Here’s what it looks like when you talk to your central processing unit:
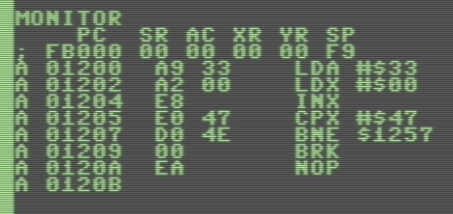
Shocking, isn’t it? That’s as low-level as it gets. Let me see if I can explain what’s happening here:
Those cryptic three-letter abbreviations on the right are Mnemonics (LDA, LDX, BNE, etc) which are there for our benefit rather than the computer’s. Think of those as commands we’re issuing, much like in BASIC. To the left of those Mnemonics are operands (#$33, $1257, etc) which are much like the parameters a command would take. For example, LDA #$33 means “load the value of hex 33 into the A register”.
Each CPU has their own set of Mnemonics (or instructions), and this example we’re talking about the MOS 6502/6510 instruction set specifically. The principles however are the same for even the latest Intel and AMD processors. They have their own set of instructions of course, but other than being faster, having more registers and being able to address more memory, not a lot has changed since 1975.
Mnemonics are still relatively high-level and not something that the computer can understand. Which is why on the left hand side of those Menmonics we’ll see what they look like translated to the computer: A9 33 is the same as LDA #$33 – LDA is translated into A9, and the operand stays the same. So far so good.
Quick aside: earlier I said that computers only understand binary values (i.e. ON or OFF, 1 or 0, and so forth) – now I’m showing you hexadecimal numbers. It’s something that’s been puzzling me for many years, and only since I read a book by the legendary Jim Butterfield I know that “hexadecimal is used for the benefit of HUMANS, not computers”. Quite an eye opener: the computer doesn’t care how we display or communicate numbers. But for us there is a huge difference in typing either of the following:
- 11111111 (binary)
- 255 (decimal)
- FF (hex)
They all represent the same value, and clearly FF is the shortest. Hence it has been decided by humans long extinct to use hex for low-level programming. End of aside.

Going back to the screenshot, let’s take a look at the left hand side of each row, starting with A. Each of these Mnemonics take up one byte in memory, and each operand for those takes up another one or two bytes. The right hand side next to the A (01200, 01202) tells us where those instructions are stored in memory – all in hex. In this case I’m using a C128 so we’ll have an extra digit in front of the actual address (0 in front of the 1200) which shows which memory bank we’re looking at – safe to ignore for now. 1200 is the actual address of the first instruction.
Those can be thought of almost as the equivalent of line numbers in BASIC, except that we can’t simply insert something in between two values – we can only overwrite existing instructions, they won’t magically move towards the bottom of our listing. It’s low-level after all.
To run this programme, all we’d tell the CPU is where to start “running” – and it will go and try, one instruction after the other. As long as the memory locations can be executed or interpreted, the CPU will do what we ask. If it encounters a BRK or RTS statement it will stop. If it encounters something that’s not an instruction it may crash, or do something rash. To run our programme, we can either issue G1200 from the monitor, or type SYS 4608 from BASIC (the decimal equivalent of 1200).
Input Tools
Now that we know what Machine Language looks like, you may wonder how we’re getting it into memory. There are tools that help us do this, one of them is a Machine Language Monitor – as seen above. They used to come either as loadable programmes, cartridges, or were built-in to the OS. On the C128 and Plus/4 just type MONITOR and you’ll see something like in the screenshot above.
 On the cheapskate C64 and VIC20 you could get a cartridge which launches a monitor. One of the popular ones was HESMON (for the VIC-20) and HESMON 64 (for the C64, also known as HESMON v2.0).
On the cheapskate C64 and VIC20 you could get a cartridge which launches a monitor. One of the popular ones was HESMON (for the VIC-20) and HESMON 64 (for the C64, also known as HESMON v2.0).
I was lucky enough to get a brand new one from Jim Drew over at CBMstuff.com – if you’re interested, he may have a few left.
Those monitors let you input Mnemonics into memory and translate them into those cryptic numbers I’ve shown you earlier. This process is called assembling, and Machine Language is therefore sometimes called Assembly or Assembly Language.
Monitors can display raw memory in hex and ASCII and let you type in each byte. Not such a good pastime because it’s totally meaningless for us humans. We’re better off assembling directly into memory using those Mnemonics. Likewise, we can use the monitor to disassemble memory locations . Here the process of displaying raw memory is translated back into Mnemonics. This Disassembler allows us to have a peek at what Machine Language programmes are up to once they’re in memory. Note that it’s not always helpful because not every location in memory is necessarily part of a programme.
Assemblers
Writing longer programmes directly into memory has its distinct disadvantages of course:
- How do you insert something in the middle of the programme?
- How can you maintain jumps to addresses when these change during development?
- JSR $1267 doesn’t sound meaningful when dealing with 300 subroutines.
- You can’t comment code to remind you what your tired brain did at location x.
To combat those and other problems, Assemblers have been invented. Those are programmes that let you use a combination of Menmonics and other instructions, as well as labels to specific points in the code (much like GOSUB labels). They work without line numbers, so all you do is to type your Mnemonics into a long text list. Then the Assembler goes to work and puts it all into memory.
When you make a change to the source code (by inserting or removing something), the Assembler puts your programme back into memory reordered, and therefore it remains executable. Addresses you refer to by labels change dynamically and the whole process is much easier than assembling directly into memory.
I must admit that I’ve not used those yet, because I’m still looking for a gentle introduction and documentation to such Assemblers – and I haven’t found any yet. Note that an Assembler (much like a Compiler) doesn’t necessarily have to run on the target machine – it can run on a different architecture. Several 6502 assemblers for modern machines exist that run under Windows and Linux, but create code for the C64. Those are known as Cross-Assemblers.
Compilers
Compilers work a bit like Assemblers, but they go a long step further: essentially they too deliver machine language executable code to the CPU, but they do so by translating a higher-leverl language. You wouldn’t write in Machine Code Mnemonics, but rather in something like Objective-C, Java or god knows what else. Swift even. Those instructions are much more geared towards how we humans think, but are far away from what a machine can execute. Here’s a snipped of Objective-C:
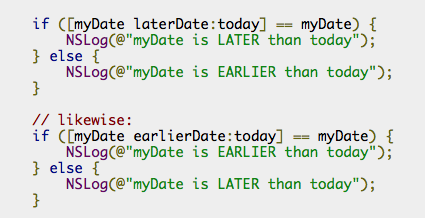
The Compiler’s job is a lot tougher and is much like what an Interpreter does on-the-fly. The only difference is that the Compiler can do its job before the executable file is needed, and technically work as long and as hard as he likes.
When I create an iPhone app, the Compiler translates something the iPhone can execute – this happens on my Mac, so the Compiler (LLVM) also runs on a different architecture than my target (the iPhone). For the C64 there were compilers which would re-write a BASIC programme to be an exclusive Machine Language programme – obviously taking quite a while due to limited CPU power. But again the principles were the same back then as they are today.
Once a Compiler has finished, only the machine executable file is distributed. Therefore, it’s almost impossible to translate the compiled programme back into Source Code. There are Decompilers which make a good guess as to what the source may have looked like, but as far as I understand it’s impossible to re-create the original source code with a Decompiler.